Reuse
Shared Core LoRA
A shared low-rank memory path captures reusable structure across tasks and offers a stable base for later adaptation.
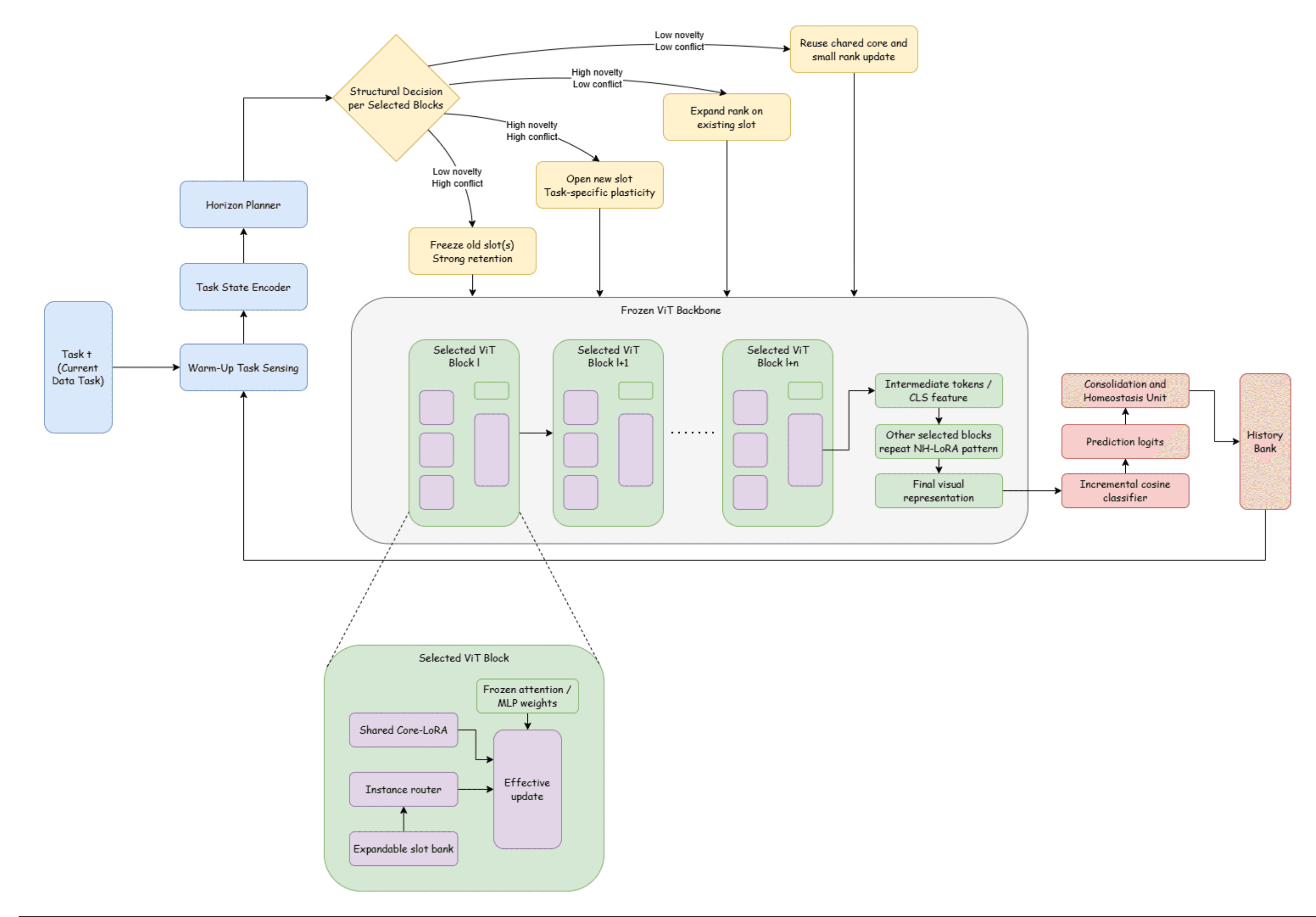
NH-LoRA explores parameter-efficient continual learning where a frozen Vision Transformer is adapted through structurally controlled low-rank modules.
In rehearsal-free class-incremental learning, the model receives new classes sequentially and cannot store previous task data. The method must learn new classes while preserving prior knowledge without replay.
Instead of assigning one static adapter design to every task, NH-LoRA treats adapter structure as a controllable state. The system senses the current task, estimates novelty and conflict, then allocates low-rank capacity where it is needed.
The diagram below is migrated from the original research assets and presented as the primary architecture reference.
A shared low-rank memory path captures reusable structure across tasks and offers a stable base for later adaptation.
A bank of task-specific low-rank slots expands or activates capacity when new evidence suggests that shared memory is insufficient.
A lightweight router selects sparse slot pathways per sample, limiting unnecessary adapter interference during inference.
A planner consumes task-state signals and predicts layer-wise novelty, conflict, rank budget, shared contribution, and consolidation pressure.
Freeze the Vision Transformer backbone and initialize compact shared low-rank memory.
Run warm-up sensing on the incoming task to summarize feature statistics, gradients, similarity, and uncertainty.
Use the Horizon Planner to decide where to reuse, expand, open, freeze, merge, or prune capacity.
Train NH-LoRA modules and the incremental classifier head while applying retention-oriented objectives when history is available.
Consolidate stable updates after each task and store the task summary in the history bank.
Encode the sample with the frozen backbone.
Use the Instance Router to activate a sparse subset of relevant task slots.
Combine shared low-rank memory with selected slot updates.
Predict through the incremental classifier head with minimized slot interference.
A continual learning setup where previous task samples are not stored or replayed.
A compact trainable update that approximates a larger weight change through low-rank matrices.
A module that summarizes the current task into signals used for structural planning.
Post-task regulation that keeps useful capacity and removes or merges redundant structure.